Sharding
4 min read
- Authors
- Name
- Karan Pratap Singh
- @karan_6864



Table of Contents
Before we discuss sharding, let's talk about data partitioning:
Data Partitioning
Data partitioning is a technique to break up a database into many smaller parts. It is the process of splitting up a database or a table across multiple machines to improve the manageability, performance, and availability of a database.
Methods
There are many different ways one could use to decide how to break up an application database into multiple smaller DBs. Below are two of the most popular methods used by various large-scale applications:
Horizontal Partitioning (or Sharding)
In this strategy, we split the table data horizontally based on the range of values defined by the partition key. It is also referred to as database sharding.
Vertical Partitioning
In vertical partitioning, we partition the data vertically based on columns. We divide tables into relatively smaller tables with few elements, and each part is present in a separate partition.
In this tutorial, we will specifically focus on sharding.
What is sharding?
Sharding is a database architecture pattern related to horizontal partitioning, which is the practice of separating one table's rows into multiple different tables, known as partitions or shards. Each partition has the same schema and columns, but also a subset of the shared data. Likewise, the data held in each is unique and independent of the data held in other partitions.

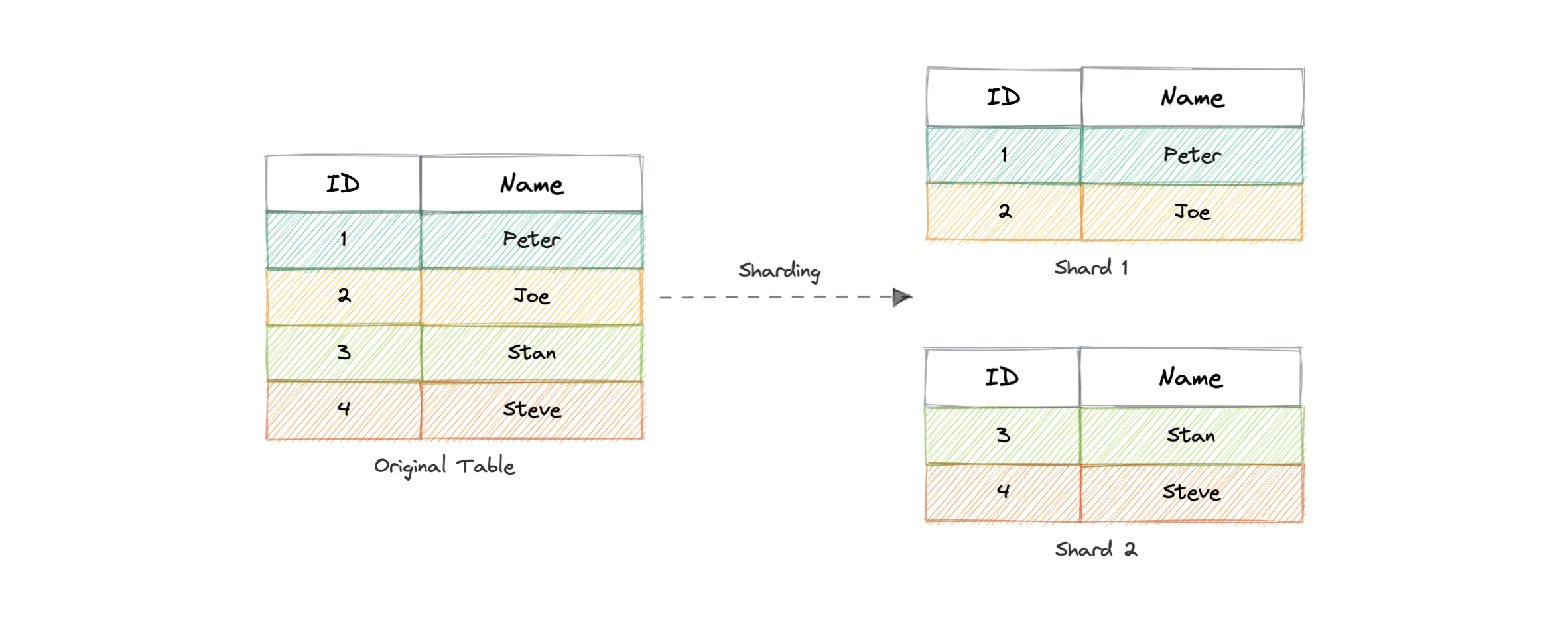
The justification for data sharding is that, after a certain point, it is cheaper and more feasible to scale horizontally by adding more machines than to scale it vertically by adding powerful servers. Sharding can be implemented at both application or the database level.
Partitioning criteria
There are a large number of criteria available for data partitioning. Some most commonly used criteria are:
Hash-Based
This strategy divides the rows into different partitions based on a hashing algorithm rather than grouping database rows based on continuous indexes.
The disadvantage of this method is that dynamically adding/removing database servers becomes expensive.
List-Based
In list-based partitioning, each partition is defined and selected based on the list of values on a column rather than a set of contiguous ranges of values.
Range Based
Range partitioning maps data to various partitions based on ranges of values of the partitioning key. In other words, we partition the table in such a way that each partition contains rows within a given range defined by the partition key.
Ranges should be contiguous but not overlapping, where each range specifies a non-inclusive lower and upper bound for a partition. Any partitioning key values equal to or higher than the upper bound of the range are added to the next partition.
Composite
As the name suggests, composite partitioning partitions the data based on two or more partitioning techniques. Here we first partition the data using one technique, and then each partition is further subdivided into sub-partitions using the same or some other method.
Advantages
But why do we need sharding? Here are some advantages:
- Availability: Provides logical independence to the partitioned database, ensuring the high availability of our application. Here individual partitions can be managed independently.
- Scalability: Proves to increase scalability by distributing the data across multiple partitions.
- Security: Helps improve the system's security by storing sensitive and non-sensitive data in different partitions. This could provide better manageability and security to sensitive data.
- Query Performance: Improves the performance of the system. Instead of querying the whole database, now the system has to query only a smaller partition.
- Data Manageability: Divides tables and indexes into smaller and more manageable units.
Disadvantages
- Complexity: Sharding increases the complexity of the system in general.
- Joins across shards: Once a database is partitioned and spread across multiple machines it is often not feasible to perform joins that span multiple database shards. Such joins will not be performance efficient since data has to be retrieved from multiple servers.
- Rebalancing: If the data distribution is not uniform or there is a lot of load on a single shard, in such cases, we have to rebalance our shards so that the requests are as equally distributed among the shards as possible.
When to use sharding?
Here are some reasons why sharding might be the right choice:
- Leveraging existing hardware instead of high-end machines.
- Maintain data in distinct geographic regions.
- Quickly scale by adding more shards.
- Better performance as each machine is under less load.
- When more concurrent connections are required.