14 min read
- Authors
- Name
- Karan Pratap Singh
- @karan_6864



Table of Contents
- What is WhatsApp?
- Requirements
- Functional requirements
- Non-functional requirements
- Extended requirements
- Estimation and Constraints
- Traffic
- Storage
- Bandwidth
- High-level estimate
- Data model design
- What kind of database should we use?
- API design
- Get all chats or groups
- Get messages
- Send message
- Join or leave a channel
- High-level design
- Architecture
- Real-time messaging
- Last seen
- Notifications
- Read receipts
- Design
- Detailed design
- Data Partitioning
- Caching
- Media access and storage
- Content Delivery Network (CDN)
- API gateway
- Identify and resolve bottlenecks
Let's design a WhatsApp like instant messaging service, similar to services like Facebook Messenger, and WeChat.
What is WhatsApp?
WhatsApp is a chat application that provides instant messaging services to its users. It is one of the most used mobile applications on the planet, connecting over 2 billion users in 180+ countries. WhatsApp is also available on the web.
Requirements
Our system should meet the following requirements:
Functional requirements
- Should support one-on-one chat.
- Group chats (max 100 people).
- Should support file sharing (image, video, etc.).
Non-functional requirements
- High availability with minimal latency.
- The system should be scalable and efficient.
Extended requirements
- Sent, Delivered, and Read receipts of the messages.
- Show the last seen time of users.
- Push notifications.
Estimation and Constraints
Let's start with the estimation and constraints.
Note: Make sure to check any scale or traffic-related assumptions with your interviewer.
Traffic
Let us assume we have 50 million daily active users (DAU) and on average each user sends at least 10 messages to 4 different people every day. This gives us 2 billion messages per day.
Messages can also contain media such as images, videos, or other files. We can assume that 5 percent of messages are media files shared by the users, which gives us additional 100 million files we would need to store.
What would be Requests Per Second (RPS) for our system?
2 billion requests per day translate into 24K requests per second.
Storage
If we assume each message on average is 100 bytes, we will require about 200 GB of database storage every day.
As per our requirements, we also know that around 5 percent of our daily messages (100 million) are media files. If we assume each file is 100 KB on average, we will require 10 TB of storage every day.
And for 10 years, we will require about 38 PB of storage.
Bandwidth
As our system is handling 10.2 TB of ingress every day, we will require a minimum bandwidth of around 120 MB per second.
High-level estimate
Here is our high-level estimate:
| Type | Estimate |
|---|---|
| Daily active users (DAU) | 50 million |
| Requests per second (RPS) | 24K/s |
| Storage (per day) | ~10.2 TB |
| Storage (10 years) | ~38 PB |
| Bandwidth | ~120 MB/s |
Data model design
This is the general data model which reflects our requirements.

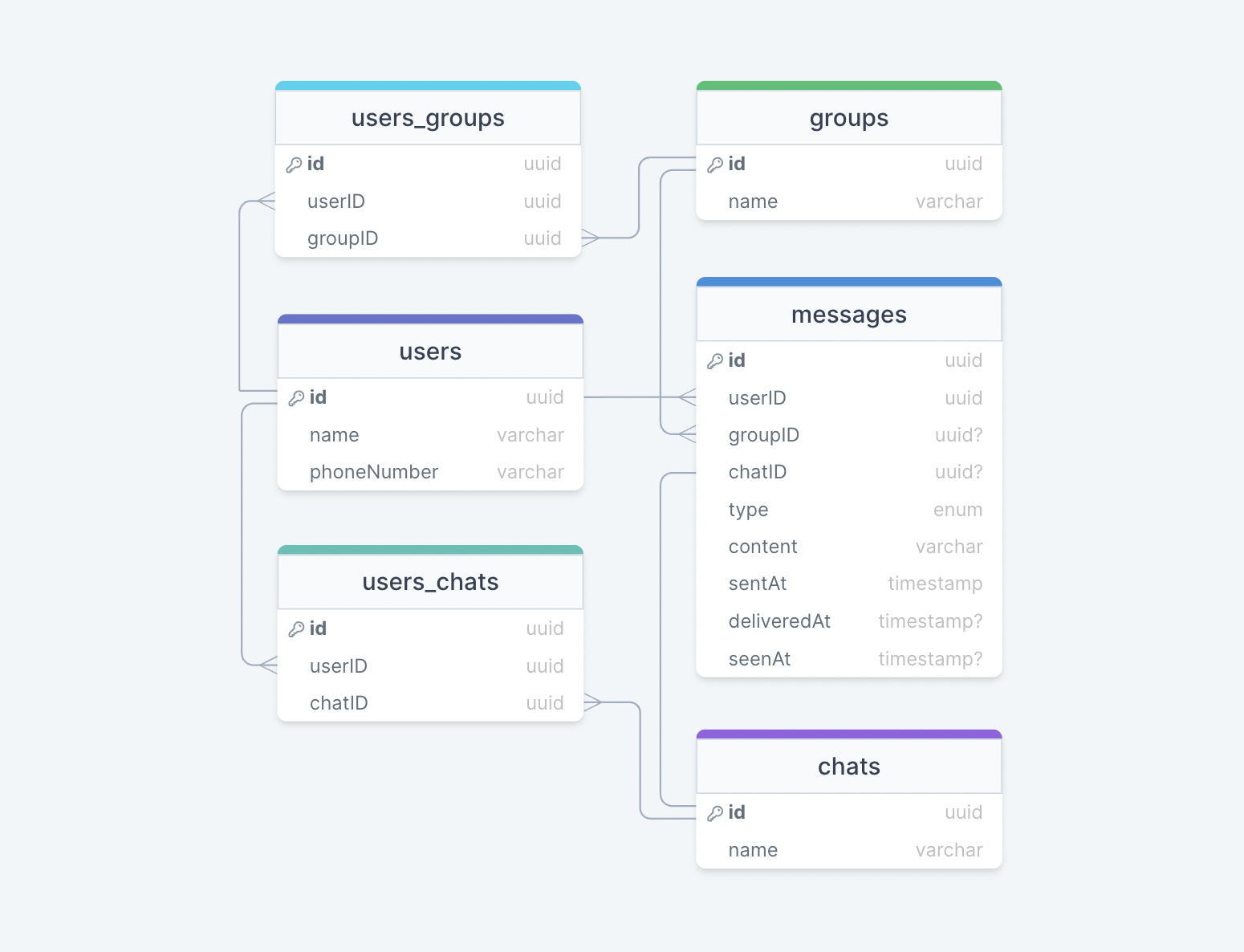
We have the following tables:
users
This table will contain a user's information such as name, phoneNumber, and other details.
messages
As the name suggests, this table will store messages with properties such as type (text, image, video, etc.), content, and timestamps for message delivery. The message will also have a corresponding chatID or groupID.
chats
This table basically represents a private chat between two users and can contain multiple messages.
users_chats
This table maps users and chats as multiple users can have multiple chats (N:M relationship) and vice versa.
groups
This table represents a group made up of multiple users.
users_groups
This table maps users and groups as multiple users can be a part of multiple groups (N:M relationship) and vice versa.
What kind of database should we use?
While our data model seems quite relational, we don't necessarily need to store everything in a single database, as this can limit our scalability and quickly become a bottleneck.
We will split the data between different services each having ownership over a particular table. Then we can use a relational database such as PostgreSQL or a distributed NoSQL database such as Apache Cassandra for our use case.
API design
Let us do a basic API design for our services:
Get all chats or groups
This API will get all chats or groups for a given userID.
getAll(userID: UUID): Chat[] | Group[]
Parameters
User ID (UUID): ID of the current user.
Returns
Result (Chat[] | Group[]): All the chats and groups the user is a part of.
Get messages
Get all messages for a user given the channelID (chat or group id).
getMessages(userID: UUID, channelID: UUID): Message[]
Parameters
User ID (UUID): ID of the current user.
Channel ID (UUID): ID of the channel (chat or group) from which messages need to be retrieved.
Returns
Messages (Message[]): All the messages in a given chat or group.
Send message
Send a message from a user to a channel (chat or group).
sendMessage(userID: UUID, channelID: UUID, message: Message): boolean
Parameters
User ID (UUID): ID of the current user.
Channel ID (UUID): ID of the channel (chat or group) user wants to send a message to.
Message (Message): The message (text, image, video, etc.) that the user wants to send.
Returns
Result (boolean): Represents whether the operation was successful or not.
Join or leave a channel
Allows the user to join or leave a channel (chat or group).
joinGroup(userID: UUID, channelID: UUID): boolean
leaveGroup(userID: UUID, channelID: UUID): boolean
Parameters
User ID (UUID): ID of the current user.
Channel ID (UUID): ID of the channel (chat or group) the user wants to join or leave.
Returns
Result (boolean): Represents whether the operation was successful or not.
High-level design
Now let us do a high-level design of our system.
Architecture
We will be using microservices architecture since it will make it easier to horizontally scale and decouple our services. Each service will have ownership of its own data model. Let's try to divide our system into some core services.
User Service
This is an HTTP-based service that handles user-related concerns such as authentication and user information.
Chat Service
The chat service will use WebSockets to establish connections with the client to handle chat and group message-related functionality. We can also use cache to keep track of all the active connections, sort of like sessions which will help us determine if the user is online or not.
Notification Service
This service will simply send push notifications to the users. It will be discussed in detail separately.
Presence Service
The presence service will keep track of the last seen status of all users. It will be discussed in detail separately.
Media service
This service will handle the media (images, videos, files, etc.) uploads. It will be discussed in detail separately.
What about inter-service communication and service discovery?
Since our architecture is microservices-based, services will be communicating with each other as well. Generally, REST or HTTP performs well but we can further improve the performance using gRPC which is more lightweight and efficient.
Service discovery is another thing we will have to take into account. We can also use a service mesh that enables managed, observable, and secure communication between individual services.
Note: Learn more about REST, GraphQL, gRPC and how they compare with each other.
Real-time messaging
How do we efficiently send and receive messages? We have two different options:
Pull model
The client can periodically send an HTTP request to servers to check if there are any new messages. This can be achieved via something like Long polling.
Push model
The client opens a long-lived connection with the server and once new data is available it will be pushed to the client. We can use WebSockets or Server-Sent Events (SSE) for this.
The pull model approach is not scalable as it will create unnecessary request overhead on our servers and most of the time the response will be empty, thus wasting our resources. To minimize latency, using the push model with WebSockets is a better choice because then we can push data to the client once it's available without any delay, given that the connection is open with the client. Also, WebSockets provide full-duplex communication, unlike Server-Sent Events (SSE) which are only unidirectional.
Note: Learn more about Long polling, WebSockets, Server-Sent Events (SSE).
Last seen
To implement the last seen functionality, we can use a heartbeat mechanism, where the client can periodically ping the servers indicating its liveness. Since this needs to be as low overhead as possible, we can store the last active timestamp in the cache as follows:
| Key | Value |
|---|---|
| User A | 2022-07-01T14:32:50 |
| User B | 2022-07-05T05:10:35 |
| User C | 2022-07-10T04:33:25 |
This will give us the last time the user was active. This functionality will be handled by the presence service combined with Redis or Memcached as our cache.
Another way to implement this is to track the latest action of the user, once the last activity crosses a certain threshold, such as "user hasn't performed any action in the last 30 seconds", we can show the user as offline and last seen with the last recorded timestamp. This will be more of a lazy update approach and might benefit us over heartbeat mechanism in certain cases.
Notifications
Once a message is sent in a chat or a group, we will first check if the recipient is active or not, we can get this information by taking the user's active connection and last seen into consideration.
If the recipient is not active, the chat service will add an event to a message queue with additional metadata such as the client's device platform which will be used to route the notification to the correct platform later on.
The notification service will then consume the event from the message queue and forward the request to Firebase Cloud Messaging (FCM) or Apple Push Notification Service (APNS) based on the client's device platform (Android, iOS, web, etc). We can also add support for email and SMS.
Why are we using a message queue?
Since most message queues provide best-effort ordering which ensures that messages are generally delivered in the same order as they're sent and that a message is delivered at least once which is an important part of our service functionality.
While this seems like a classic publish-subscribe use case, it is actually not as mobile devices and browsers each have their own way of handling push notifications. Usually, notifications are handled externally via Firebase Cloud Messaging (FCM) or Apple Push Notification Service (APNS) unlike message fan-out which we commonly see in backend services. We can use something like Amazon SQS or RabbitMQ to support this functionality.
Read receipts
Handling read receipts can be tricky, for this use case we can wait for some sort of Acknowledgment (ACK) from the client to determine if the message was delivered and update the corresponding deliveredAt field. Similarly, we will mark the message as seen once the user opens the chat and update the corresponding seenAt timestamp field.
Design
Now that we have identified some core components, let's do the first draft of our system design.

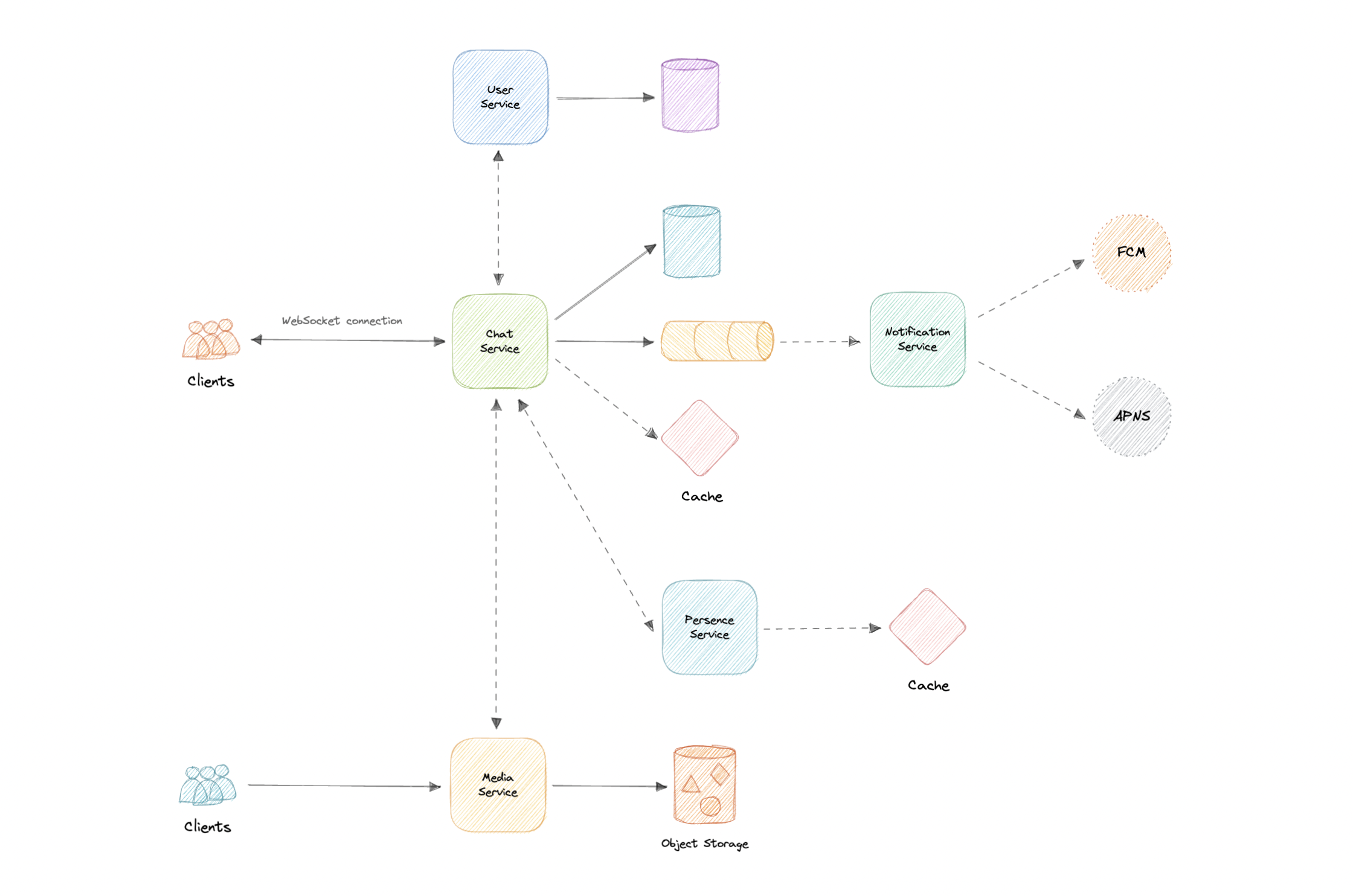
Detailed design
It's time to discuss our design decisions in detail.
Data Partitioning
To scale out our databases we will need to partition our data. Horizontal partitioning (aka Sharding) can be a good first step. We can use partitions schemes such as:
- Hash-Based Partitioning
- List-Based Partitioning
- Range Based Partitioning
- Composite Partitioning
The above approaches can still cause uneven data and load distribution, we can solve this using Consistent hashing.
For more details, refer to Sharding and Consistent Hashing.
Caching
In a messaging application, we have to be careful about using cache as our users expect the latest data, but many users will be requesting the same messages, especially in a group chat. So, to prevent usage spikes from our resources we can cache older messages.
Some group chats can have thousands of messages and sending that over the network will be really inefficient, to improve efficiency we can add pagination to our system APIs. This decision will be helpful for users with limited network bandwidth as they won't have to retrieve old messages unless requested.
Which cache eviction policy to use?
We can use solutions like Redis or Memcached and cache 20% of the daily traffic but what kind of cache eviction policy would best fit our needs?
Least Recently Used (LRU) can be a good policy for our system. In this policy, we discard the least recently used key first.
How to handle cache miss?
Whenever there is a cache miss, our servers can hit the database directly and update the cache with the new entries.
For more details, refer to Caching.
Media access and storage
As we know, most of our storage space will be used for storing media files such as images, videos, or other files. Our media service will be handling both access and storage of the user media files.
But where can we store files at scale? Well, object storage is what we're looking for. Object stores break data files up into pieces called objects. It then stores those objects in a single repository, which can be spread out across multiple networked systems. We can also use distributed file storage such as HDFS or GlusterFS.
Fun fact: WhatsApp deletes media on its servers once it has been downloaded by the user.
We can use object stores like Amazon S3, Azure Blob Storage, or Google Cloud Storage for this use case.
Content Delivery Network (CDN)
Content Delivery Network (CDN) increases content availability and redundancy while reducing bandwidth costs. Generally, static files such as images, and videos are served from CDN. We can use services like Amazon CloudFront or Cloudflare CDN for this use case.
API gateway
Since we will be using multiple protocols like HTTP, WebSocket, TCP/IP, deploying multiple L4 (transport layer) or L7 (application layer) type load balancers separately for each protocol will be expensive. Instead, we can use an API Gateway that supports multiple protocols without any issues.
API Gateway can also offer other features such as authentication, authorization, rate limiting, throttling, and API versioning which will improve the quality of our services.
We can use services like Amazon API Gateway or Azure API Gateway for this use case.
Identify and resolve bottlenecks

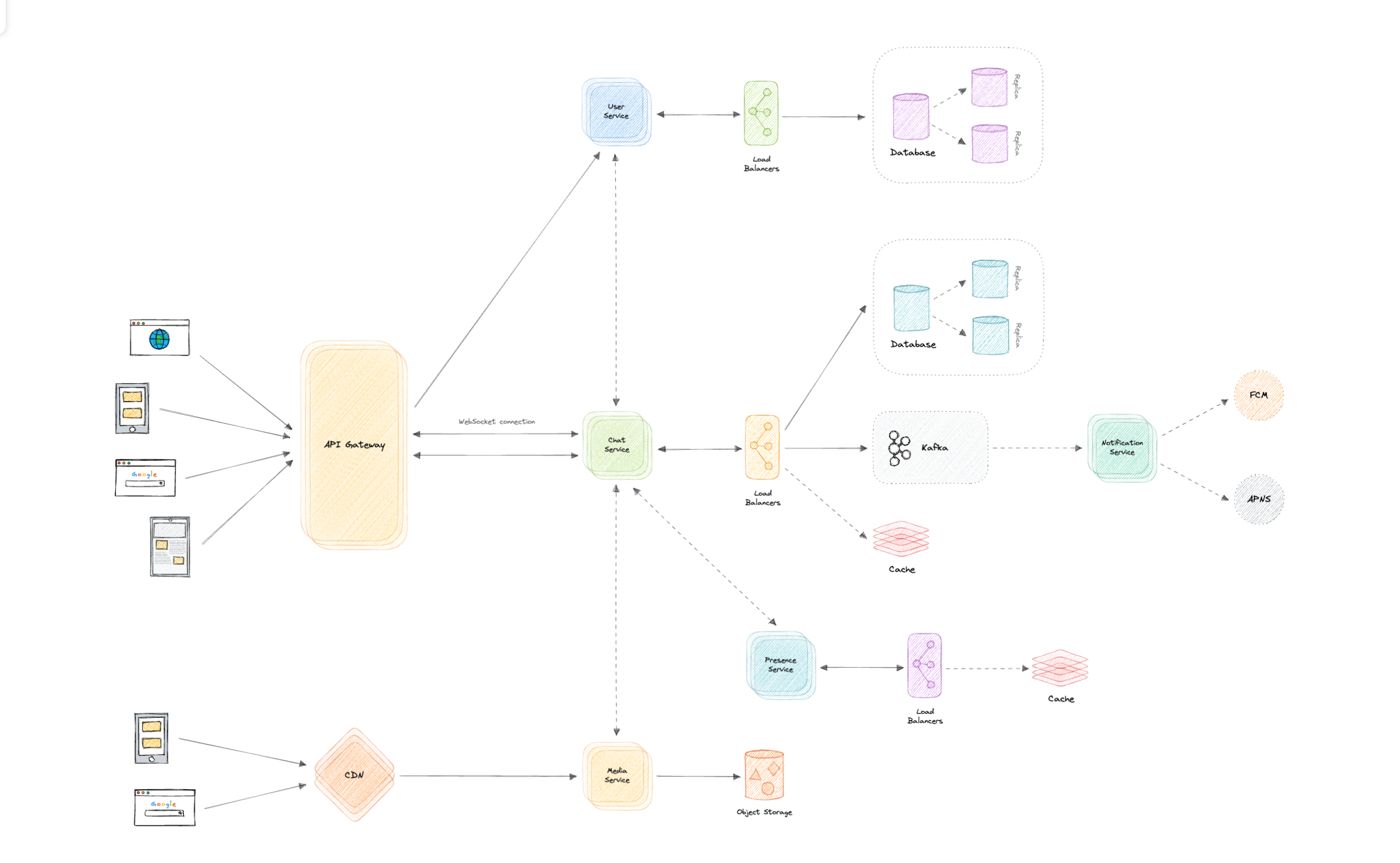
Let us identify and resolve bottlenecks such as single points of failure in our design:
- "What if one of our services crashes?"
- "How will we distribute our traffic between our components?"
- "How can we reduce the load on our database?"
- "How to improve the availability of our cache?"
- "Wouldn't API Gateway be a single point of failure?"
- "How can we make our notification system more robust?"
- "How can we reduce media storage costs"?
- "Does chat service has too much responsibility?"
To make our system more resilient we can do the following:
- Running multiple instances of each of our services.
- Introducing load balancers between clients, servers, databases, and cache servers.
- Using multiple read replicas for our databases.
- Multiple instances and replicas for our distributed cache.
- We can have a standby replica of our API Gateway.
- Exactly once delivery and message ordering is challenging in a distributed system, we can use a dedicated message broker such as Apache Kafka or NATS to make our notification system more robust.
- We can add media processing and compression capabilities to the media service to compress large files similar to WhatsApp which will save a lot of storage space and reduce cost.
- We can create a group service separate from the chat service to further decouple our services.